01 — Overview
프로젝트 개요 & 목표
냉동식품 유통 ERP의 안정적 운영을 위한 하이브리드 멀티클라우드 인프라와, 그 위에서 "지금 무슨 일이 일어나는지"를 한눈에 보는 통합 관측 체계를 구축했습니다.
냉동식품(콜드체인) ERP는 재고·주문·수요예측과 현장 센서가 얽혀 있어, 장애가 어디서 시작됐는지 추적이 어렵습니다. 콘솔 클릭으로 만든 인프라는 멀티 PC·팀 협업 환경에서 재현이 불가능하고, 비용·보안 사고는 사후에야 발견됐습니다.
모든 인프라를 Terraform 코드로 선언하고, 로그·메트릭·추적 3축을 각각 가장 적합한 도구에 매칭했습니다. 대시보드·알람·데이터소스까지 jsonencode로 코드화해, 똑같은 관측 환경을 언제든 재현할 수 있게 만들었습니다.
- AWS 멀티리전 — 서울(ap-northeast-2) 메인 + 오하이오(us-east-2)를 단일 Grafana로 페더레이션, Azure로 CloudTrail 로그 재해복구 백업
- EKS 컨테이너 환경 위에 로그(Fluent Bit) · 메트릭(Prometheus) · 추적(OTel→X-Ray) 3축을 설계하고 IoT 센서 파이프라인까지 통합
- 관측 · 배포(IaC) · 보안/감사 · 비용 거버넌스 4개 영역을 3개 레포(
infra-monitoring·observability·security)로 직접 설계·구현 - 콘솔 클릭이 아닌 terraform apply 한 번으로 배포되는, 버전 관리·재현 가능한 GitOps 환경
02 — Architecture
아키텍처 구성
AWS 멀티리전을 메인으로, Azure를 재해복구 백업으로 두는 하이브리드 멀티클라우드 토폴로지. EKS·관측 3축·IoT·보안 파이프라인이 하나의 그림으로 연결됩니다.
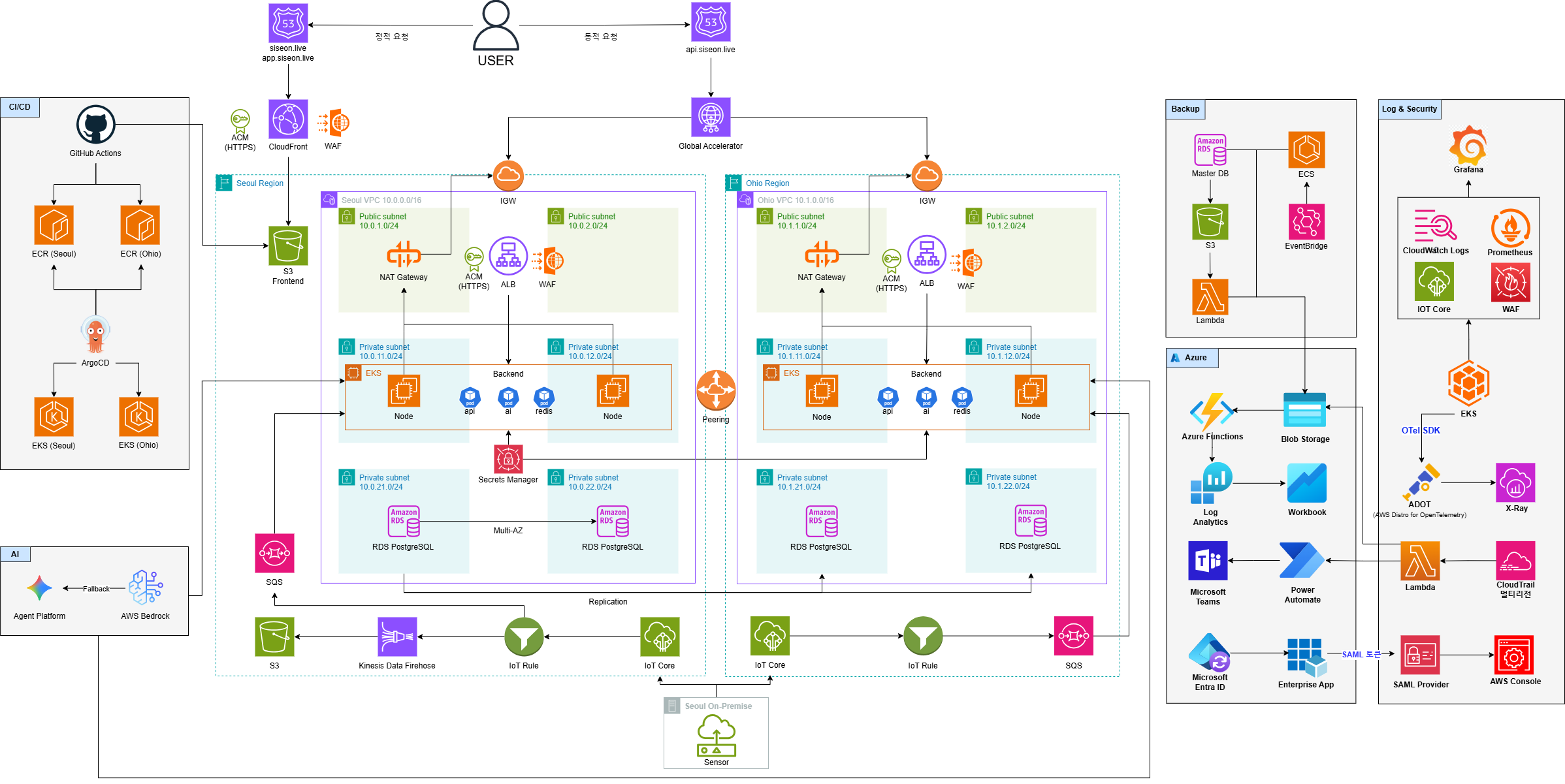
AWS 서울·오하이오 멀티리전 + Azure DR · EKS · Observability 3축 · IoT 파이프라인
AWS · ap-northeast-2
서울 (메인)
EKS seoul-cluster · Grafana/Prometheus 호스트 · ALB+ACM HTTPS · IoT·보안·비용 파이프라인
AWS · us-east-2
오하이오 (확장)
EKS 클러스터 + Prometheus 메트릭 수집(PodMonitor) · 내부 NLB로 노출 → VPC 피어링으로 서울 Grafana가 직접 쿼리
Azure · Korea Central
재해복구 (DR)
CloudTrail 로그 Blob 백업(하루 3회) · Function → Log Analytics → Monitor Workbook 페일오버 대시보드
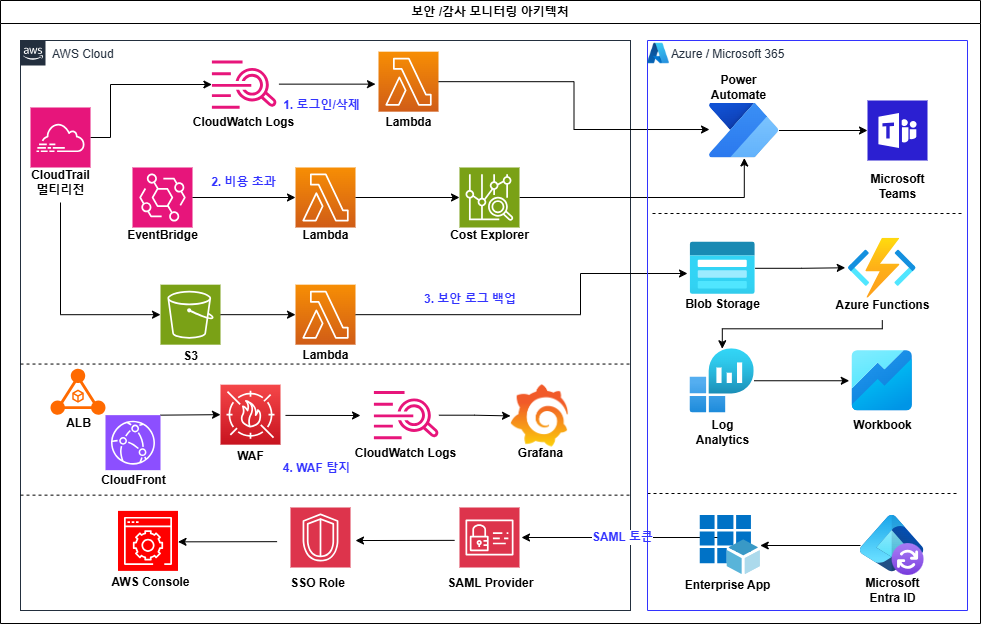
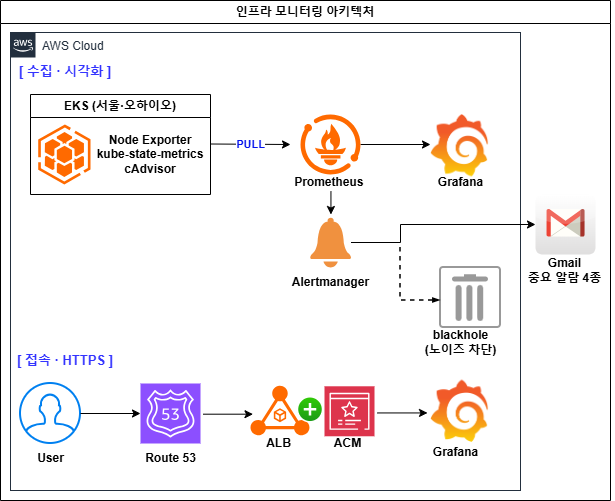
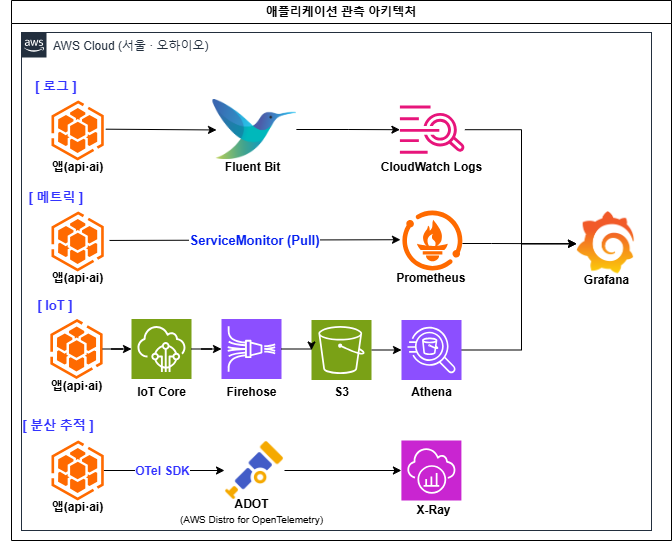
영역별 상세 아키텍처 — 보안 · 인프라 · 관측
03 — Observability
로그 · 메트릭 · 추적 3축 설계
"무엇이, 얼마나, 어디서 느려졌는가"를 각각 다른 질문으로 보고, 각 질문에 가장 적합한 도구를 매칭했습니다. 모든 축이 결국 하나의 Grafana로 모입니다.
Logs · 무슨 일이
Fluent Bit → CloudWatch
왜 — 서비스별(api/ai)로 로그 그룹을 분리하고, 검색어·레벨 변수로 여러 로그그룹을 동시 필터링해 콘솔보다 빠른 통합 뷰 제공.
Metrics · 얼마나
Prometheus → Grafana
왜 — Spring Boot(api)는 Actuator, FastAPI(ai)는 instrumentator로 노출. JVM 힙·HikariCP·Bedrock 회로차단기까지 수치로 관측.
Traces · 어디서
OTel → ADOT → X-Ray
왜 — 요청 하나가 보안필터→컨트롤러→DB, 그리고 api→ai-module까지 흐르는 구간을 ms 단위로 분해해 병목을 특정.
04 — Implementation
구현 4개 영역 · 3개 레포
관측에서 시작해 배포 자동화, 보안/감사, 비용 거버넌스까지 — 운영을 지탱하는 4개 영역을 직접 설계·구현했습니다.
- kube-prometheus-stack v58.0.0(Grafana v10.4.0)를 Helm·Terraform으로 배포 — Prometheus / Grafana / Alertmanager 일괄 구성
- Grafana 대시보드 전체를
jsonencode로 코드화(GitOps) — 노드 게이지·Pod 리소스·네트워크·재시작·서비스 상태 - 앱 메트릭: Spring Boot
/actuator/prometheus+ FastAPI/metrics→ ServiceMonitor(30s) → 처리량·에러율·응답시간·JVM힙·HikariCP·Bedrock 회로차단기·AI 예측 처리량/p95/캐시적중률 - 분산 추적: OTel → ADOT Collector → X-Ray — 요청별 보안필터·DB 구간 waterfall 분석
- IoT 센서: S3 → Glue 카탈로그 + Athena 파티션 프로젝션(2026–2030) → Grafana
- Alertmanager 알람 4종(Gmail SMTP) + blackhole로 EKS 컨트롤플레인 노이즈 억제 · k6 부하 테스트로 대시보드·알람 검증
- 전 인프라를 Terraform으로 선언 — S3 Remote Backend(
siseon-terraform-state)를 레포별 키로 분리해 멀티 PC tfstate 동기화 문제 해결 - 레포 간 배포 순서 설계:
security(CloudTrail) →observability(데이터소스) →infra-monitoring(Grafana 참조) - Helm 차트를
helm_release로 선언적 관리 · ServiceMonitor CRD 의존성을-target단계 배포로 해결 - Grafana 권한을 Node Role이 아닌 IRSA(ServiceAccount→IAM Role)로 최소 권한 부여 — Athena·Glue·CloudWatch·S3 분리
- 관측 노출을 NLB → ALB + ACM으로 전환해
grafana.siseon.liveHTTPS 제공
- CloudTrail → CloudWatch → Subscription Filter → Lambda → Power Automate → Teams 실시간 알림 — 콘솔 로그인·리소스 삭제를 채널별(aws-logins·aws-alerts)로 분배, AWS 서비스 자동작업은
sourceIPAddress기반 노이즈 필터링 - 재해복구: S3 CloudTrail 로그 → Azure Blob 하루 3회(02·10·18 KST) 백업 → Azure Function → Log Analytics → Monitor Workbook 페일오버 대시보드(KQL)
- 멀티클라우드 SSO: Azure Entra ID → AWS SAML Federation (Azure Free 플랜 한계를 IdP 방향 전환으로 우회)
- S3 Lifecycle:
30d → IA·90d → Glacier·365d → 삭제로 로그 보관 비용 최적화 - WAF 멀티리전(서울 ALB·오하이오 ALB·CloudFront) 로그를 Grafana 보안 대시보드로 통합
- 비용 모니터링을 3차에 걸쳐 재설계 — CloudWatch Billing(us-east-1) → AWS Budgets SNS → 최종 EventBridge + Lambda + Cost Explorer API
- Budgets가 동일 상태 유지 시 재발송하지 않는 한계를 매일 KST 09:00 전일 비용 강제 조회로 우회
- 크로스리전 Lambda Permission 실패를 글로벌 서비스(Budgets)로 우회하는 의사결정
- 멀티리전 전환에 따른 비용 증가($48 → $126.5)를 반영해 임계값 현실화(일 $8 / 월 $135)
05 — Distributed Tracing
분산 추적 — 요청 하나를 ms 단위로 분해
OTel SDK가 심은 컨텍스트를 ADOT Collector가 모아 X-Ray로 보냅니다. AI 예측 요청은 클라이언트 → stockops(api) → ai-module → Database 4노드로 이어지며, 아래는 실측 트레이스(약 1.76초)를 재구성한 waterfall입니다.
(Spring Security)
원격 호출
(ai-module)
실전 디버깅 (면접 골드 스토리) — prophet을 직접 부르는 generate 경로의 trace가 빌드 회귀로 끊겨 ai 세그먼트의 부모가 전부 dangling 처리되고, 한 trace에 세그먼트가 220개씩 쌓였습니다.
소스는 정상인데 배포 이미지에 계측 fix가 빠진 빌드 산출물 ↔ 소스 불일치였죠. 같은 ai를 부르지만 계측된 HTTP 클라이언트(@Observed)를 타는
Bedrock 어시스턴트 경로(/api/v1/ai/bedrock/assistant)로 우회하니, 개별 트레이스가 클라이언트 → api → ai-module → DB 4노드로 깔끔하게 이어졌습니다.
두 경로의 차이는 결국 "HTTP 클라이언트가 계측됐는가"였고, 그것을 끝까지 추적해 우회 경로를 찾아낸 경험입니다.
06 — Dashboards
Grafana 대시보드 5종 · 40여 개 커스텀 패널
인프라·앱·보안·IoT를 데이터소스별(Prometheus / CloudWatch Logs / Athena)로 매칭한 커스텀 대시보드. 패널 정의 전체가 Terraform 코드입니다.
13 panels
10 panels · api 6 + ai 4
7 panels
7 panels · 멀티리전 WAF
3 panels
+ Node Exporter · K8s Cluster/Pod
공식 템플릿 대시보드 연동
07 — Cost Governance
비용 거버넌스 — 3차에 걸친 재설계
"알림이 안 온다"는 문제의 근본 원인을 좇아 아키텍처를 두 번 갈아엎었습니다. 도구의 한계를 인정하고 우회 설계를 선택한 의사결정 기록입니다.
1차
CloudWatch Billing Alarm
(us-east-1) → SNS → Lambda
크로스리전 Lambda Permission 실패 — Billing은 us-east-1 전용
2차
AWS Budgets DAILY
→ SNS → Lambda
동일 ALARM 상태 유지 시 재발송 없음 — 첫날만 알림, 이후 매일 초과해도 무음
3차 · 현재
EventBridge + Lambda
+ Cost Explorer API
매일 KST 09:00 전일 실비용을 직접 조회 → 상태 개념 없이 임계값 초과 시 Teams 발송
08 — Tech Stack
핵심 적용 기술
IaC / GitOps
Container
Metrics
Logs / Traces
Data / IoT
Security / Cost
Azure (Multi-Cloud)
App / AI
09 — Deck & Demo
발표 자료 & 데모 영상
전체 설계·구현 과정을 담은 발표 자료와, 프로젝트 시연 데모입니다.
발표 자료 — PDF
PDF를 불러올 수 없습니다. 아래 버튼으로 다운로드해서 확인해 주세요.
⬇ PDF 다운로드프로젝트 시연 — 데모 영상
10 — Troubleshooting
장애 대응 & 트러블슈팅
3개 레포에 걸쳐 기록한 60여 건 중, 영역별 대표 사례를 추렸습니다. 문제 → 원인 → 해결의 흐름으로 정리했습니다.
✕전 패널 "No data" + connection refused
✓Prometheus가 OOMKilled — WAF 로그·멀티리전 trace 볼륨으로 메모리 부족. limit을 512Mi → 1.5Gi로 상향해 전면 복구
✕Grafana 503 Service Unavailable (간헐)
✓ALB 헬스체크 경로 /가 302 리다이렉트 → 타깃 unhealthy. healthcheck-path: /api/health로 변경
✕Grafana CrashLoopBackOff
✓sidecar와 커스텀 데이터소스 중복 등록 충돌 → defaultDatasourceEnabled=false
✕ServiceMonitor가 Service를 못 찾음
✓selector는 Deployment가 아닌 Service metadata label을 봄 → Service에 app=stockops-api 라벨 추가
✕AI 캐시 적중률이 idle에서 NaN/0%
✓increase()의 0/0=NaN 문제 → 누적 ratio PromQL(hit/total*100)로 안정화
✕Bedrock 회로차단기 패널이 파드별 중복 표시
✓max() 집계로 단일 시리즈화 — "한 파드라도 open이면 위험" 의미로 통합
✕NLB가 pending / internal로 생성
✓서브넷 kubernetes.io/role/elb 태그 추가 + aws-load-balancer-scheme: internet-facing 어노테이션
✕Load Balancer Controller IAM 권한 부족
✓DescribeListenerAttributes 등 누락 액션을 LBC 정책에 보강
✕ServiceMonitor CRD가 plan 단계에 없음
✓클린 배포 시 CRD 미존재 → -target=helm_release로 먼저 설치 후 전체 apply
✕Helm 릴리스 state 충돌로 apply 실패
✓helm uninstall + terraform state rm 후 재배포로 정합성 복구
✕Grafana가 EC2 IMDS 자격증명을 못 가져옴
✓IRSA로 ServiceAccount에 IAM Role을 직접 연결해 근본 해결
✕X-Ray Service Map에 서비스 간 화살표가 안 생김
✓실제 분산 호출 + 시드 데이터(15일치 수요 이력)가 있어야 4노드 생성됨을 규명
✕generate 경로의 trace가 끊김 (빌드 회귀)
✓계측 미반영 이미지 → Bedrock 어시스턴트 경로로 우회해 4노드 정상 트레이스 확보
✕Athena named query를 Terraform으로 자동화 불가
✓aws_glue_catalog_table 리소스로 전환해 apply 한 번에 테이블 등록
✕Teams 웹훅이 갑자기 중단
✓O365 커넥터 종료 → Power Automate HTTP 트리거로 알림 파이프라인 재구축
✕보안 알림이 누락됨
✓CloudWatch Alarm은 상태 변화 없으면 무음 → Subscription Filter → Lambda 실시간 감지로 전환
✕AWS Budgets가 동일 상태에서 재발송 안 함
✓EventBridge + Cost Explorer API로 매일 전일 비용을 강제 체크
✕크로스리전 Lambda Permission 실패
✓글로벌 서비스(Budgets)로 우회해 리전 종속성 제거
✕WAF 공격 시도가 대시보드에 안 보임
✓룰이 count 모드라 ALLOW로 기록됨 → BLOCK 패널 + count-mode 룰 파싱 패널 2개로 분리
— 위는 대표 사례이며, 전체 60여 건은 각 레포의 troubleshooting 문서에 기록되어 있습니다.